Giới thiệu AWS Glue & Amazon Athena
Giới thiệu AWS Glue & Amazon Athena
AWS Glue là dịch vụ chuẩn bị dữ liệu hỗ trợ các nhà phân tích dữ liệu trong việc trích xuất - biến đổi – đẩy dữ liệu ETL(Extract - Transform - Load), tạo điều kiện để trau chuốt, làm phong phú và chuẩn hóa dữ liệu. Đồng thời nhờ có AWS Glue, thời gian cần thiết để bắt đầu phân tích dữ liệu có thể giảm từ hàng tháng xuống vài phút.
Để dữ liệu sẵn sàng cho hoạt động phân tích, trước tiên bạn cần trích xuất dữ liệu từ nhiều nguồn (ví dụ S3). Sau đó phải trau chuốt, biến đổi dữ liệu thành định dạng yêu cầu (ví dụ Parquet), đẩy dữ liệu vào cơ sở dữ liệu, kho dữ liệu và hồ dữ liệu cho quá trình phân tích sau này. Những công việc này thường được thực hiện bởi nhiều nhóm nhân lực với nhiều công cụ đa dạng khác nhau.
AWS Glue cho phép thao tác cả ở dạng mã lệnh và dạng giao diện giúp người dùng thuận tiện trong việc chuẩn bị dữ liệu. Các nhà phân tích dữ liệu có thể dễ dàng khởi tạo, chạy và theo dõi quy trình ETL với AWS Glue Studio. Ngoài ra còn có AWS Glue DataBrew giúp trau chuốt và chuẩn hóa dữ liệu một cách trực quan mà không cần phải viết mã.
Bên dưới là sơ đồ hoạt động cơ bản với sự kết hợp giữa AWS Glue và Amazon Athena
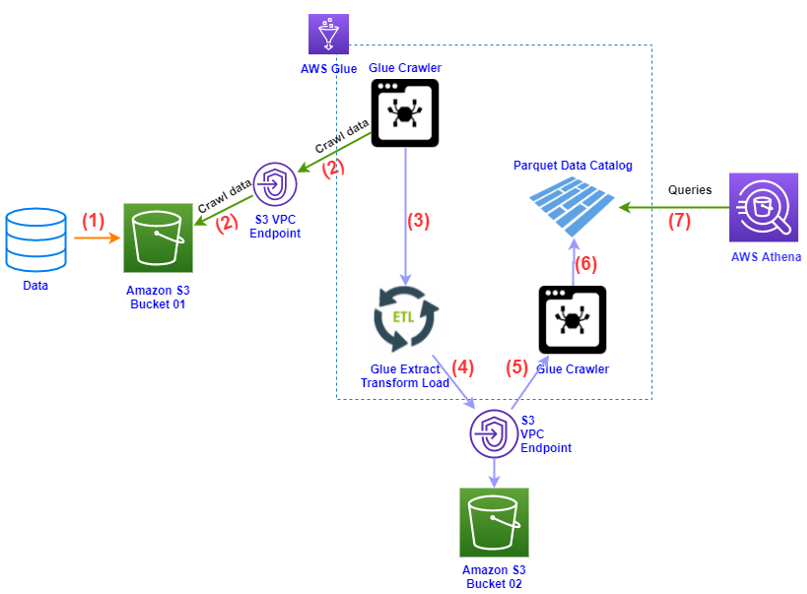
Trong đó:
- (1): Dữ liệu được đẩy lên AWS S3.
S3 chứa dữ liệu đầu vào không yêu cầu phải được cấu hình public access và cũng không cần phải cùng region với dịch vụ AWS Glue
- (2): AWS Glue sử dụng Glue Crawler để biến đổi dữ liệu trong S3 thành dạng bảng (table)
AWS Glue cần được cấp quyền GetObject and PutObject S3, nhằm cho phép Glue được truy cập vào S3 (đọc và ghi file Parquet trên S3)
- (3): Thông qua quy trình ETL, AWS Glue biến đổi dữ liệu dạng bảng thành dạng Parguet
- (4): Kết quả chuyển đổi ở bước (3) được lưu vào S3 bucket 2.
- (5)+(6): Tiếp tục sử dụng Glue Crawler biến đổi file dạng Parquet nằm trong S3 thành file Parguet Catalog.
- (7): Sử dụng Amazon Athena để query data từ AWS Glue.
S3 chứa kết quả truy vấn từ Athena phải cùng Region với Amazon Athena
Tuy nhiên trong phạm vi của bài lab, chúng ta bỏ qua các bước biến đổi dữ liệu ban đầu và chỉ làm việc trực tiếp trên file Parquet có sẵn. Cụ thể chúng ta sẽ đi xây dựng một nền tảng để phân tích chi phí và hiệu năng sử dụng, từ đó ta có thể cân bằng giữa chi phí với hiệu quả của các thành phần trong hệ thống, nhưng vẫn tuân thủ kiến trúc tối ưu của AWS (AWS Well-Architected Framework)