Introducing AWS Glue & Amazon Athena
Introducing AWS Glue & Amazon Athena
AWS Glue is a data preparation service that assists data analysts in extracting - transforming - pushing ETL(Extract - Transform - Load) data, facilitating the refining, enriching, and normalizing of data. Also, thanks to AWS Glue, the time required to start analyzing data can be reduced from months to minutes.
To make your data ready for analysis, you need to first extract data from multiple sources (e.g. S3). Then it must be refined, transformed into the required format (eg Parquet), and pushed the data into databases, data warehouses, and data lakes for later analysis. These jobs are often performed by multiple teams of people with a variety of tools.
AWS Glue allows operation both in the form of code and in the form of an interface that makes it convenient for users to prepare data. Data analysts can easily initiate, run, and monitor ETL processes with AWS Glue Studio. There is also AWS Glue DataBrew that refines and normalizes data intuitively without having to write code.
Below is a basic operation diagram with a combination of AWS Glue and Amazon Athena
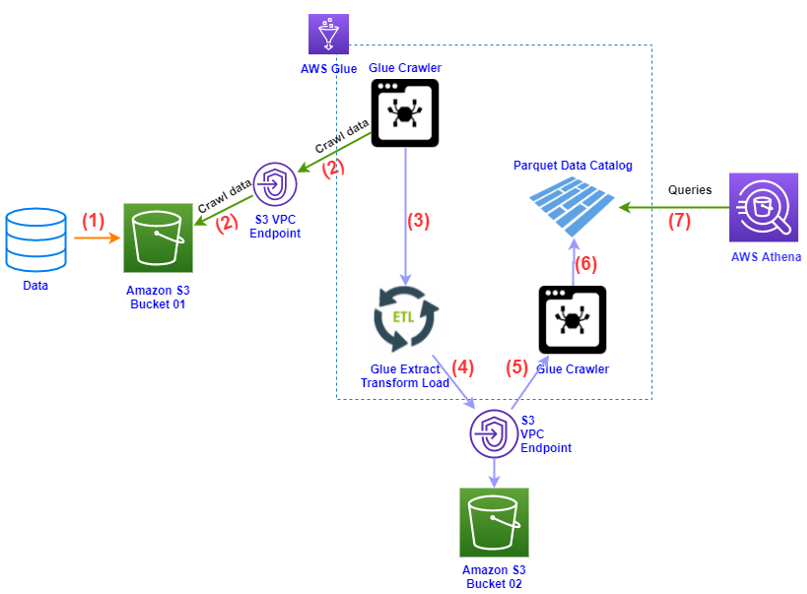
In there:
- (1): Data is pushed to AWS S3.
S3 containing input does not require public access configuration and does not need to be in the same region as the AWS Glue service.
- (2): AWS Glue uses Glue Crawler to transform the data in S3 into a table (table)
AWS Glue needs GetObject and PutObject S3 permission, to allow Glue to access S3 (read and write Parquet files on S3)
- (3): Through the ETL process, AWS Glue transforms tabular data into Parquet
- (4): The conversion results in step (3) are saved in S3 bucket 2.
- (5)+(6): Continue using Glue Crawler to convert the Parquet file located in S3 into Parquet Catalog file.
- (7): Use Amazon Athena to query data from AWS Glue.
S3 contains query results from Athena which must be the same Region as Amazon Athena
However, in the scope of the lab, we skip the initial data transformation steps and only work directly on the existing Parquet file. Specifically, we will go to build a platform for cost and performance analysis, from which we can balance the cost with the efficiency of the components in the system, but still adhere to the optimal architecture. Advantages of AWS (AWS Well-Architected Framework)