Building a database
In the lab, once we have the input data with the above path as at the beginning of the lab, we will configure AWS Glue and Crawler so that it runs on a schedule *once a day *. Crawler will scan the path containing the input Parquet file, save it on S3 and then create a database with accompanying tables. When a new version of report is available, the data sheet is automatically updated.
Amazon Athena helps us access and view parquet file contents through SQL code. Amazon Athena is a serverless solution that supports executing SQL queries on large amounts of data. Athena is charged only for scanned data, unlike a traditional database solution.
The detailed configuration steps for Amazon Athena to access data files through AWS Glue are as follows:
-
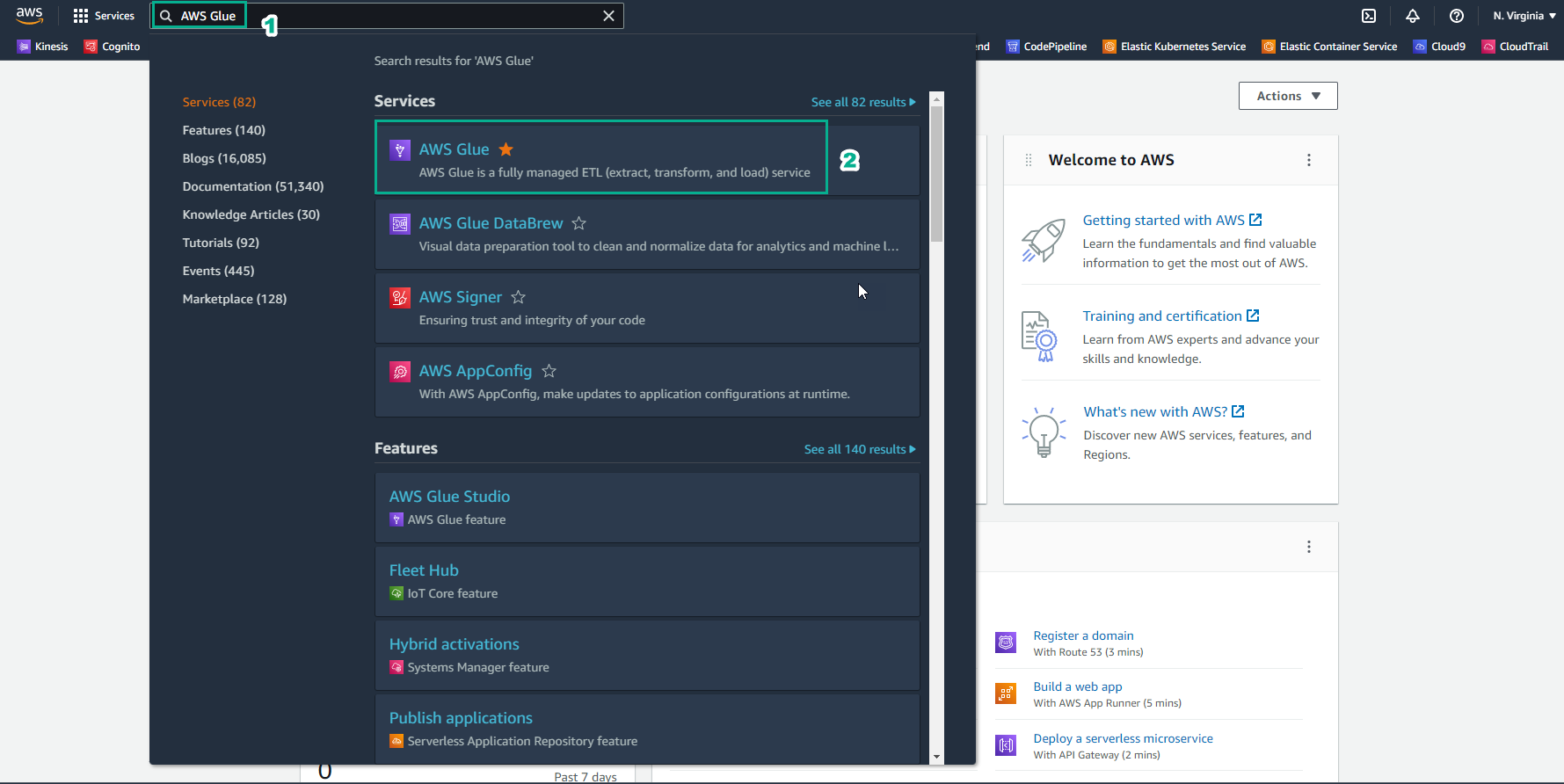
Go to AWS Management Console
- Find AWS Glue
- Select AWS Glue
-
In the AWS Glue interface
- Select Crawlers
- Select Create crawler
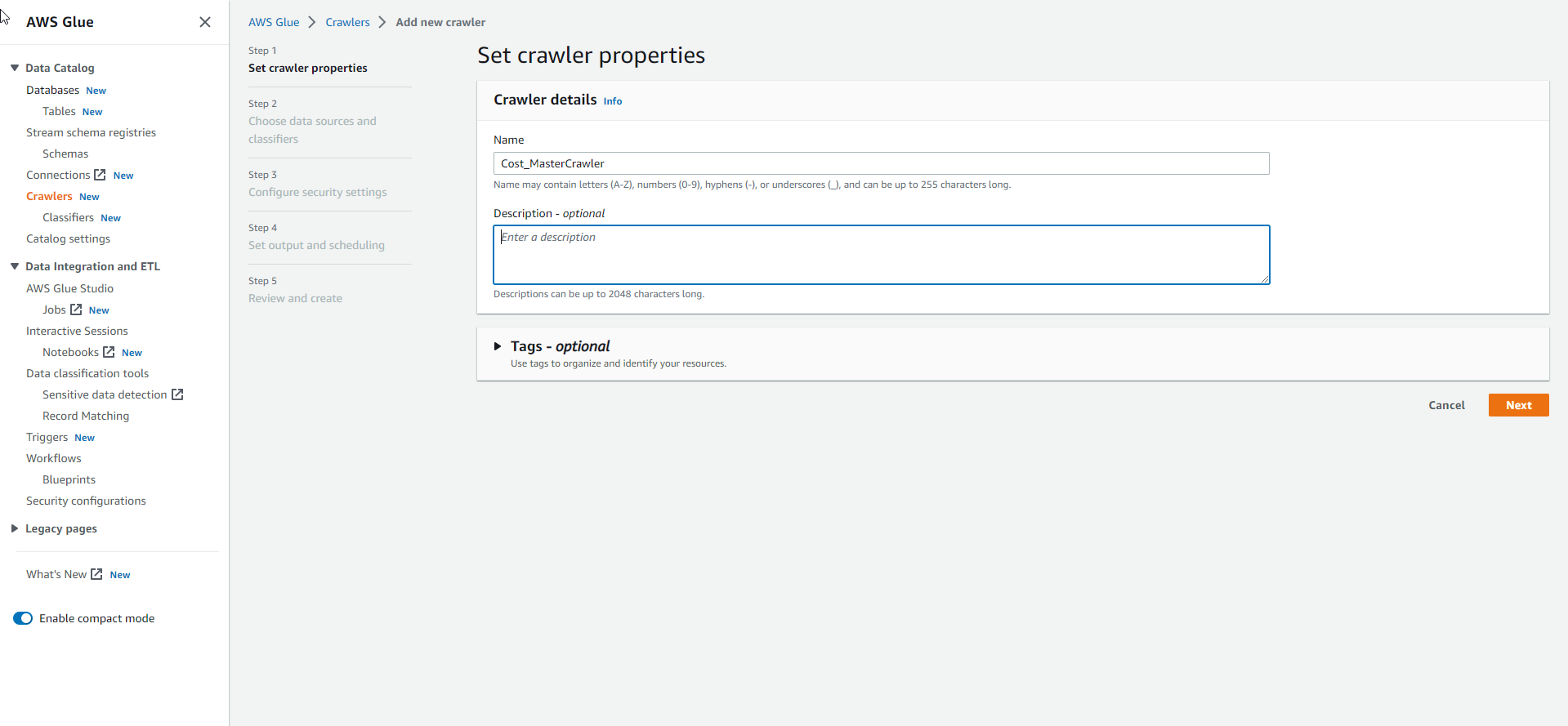
- Configure Crawler, enter Name as
Cost_MasterCrawler. Then select Next
- Select Add a data source
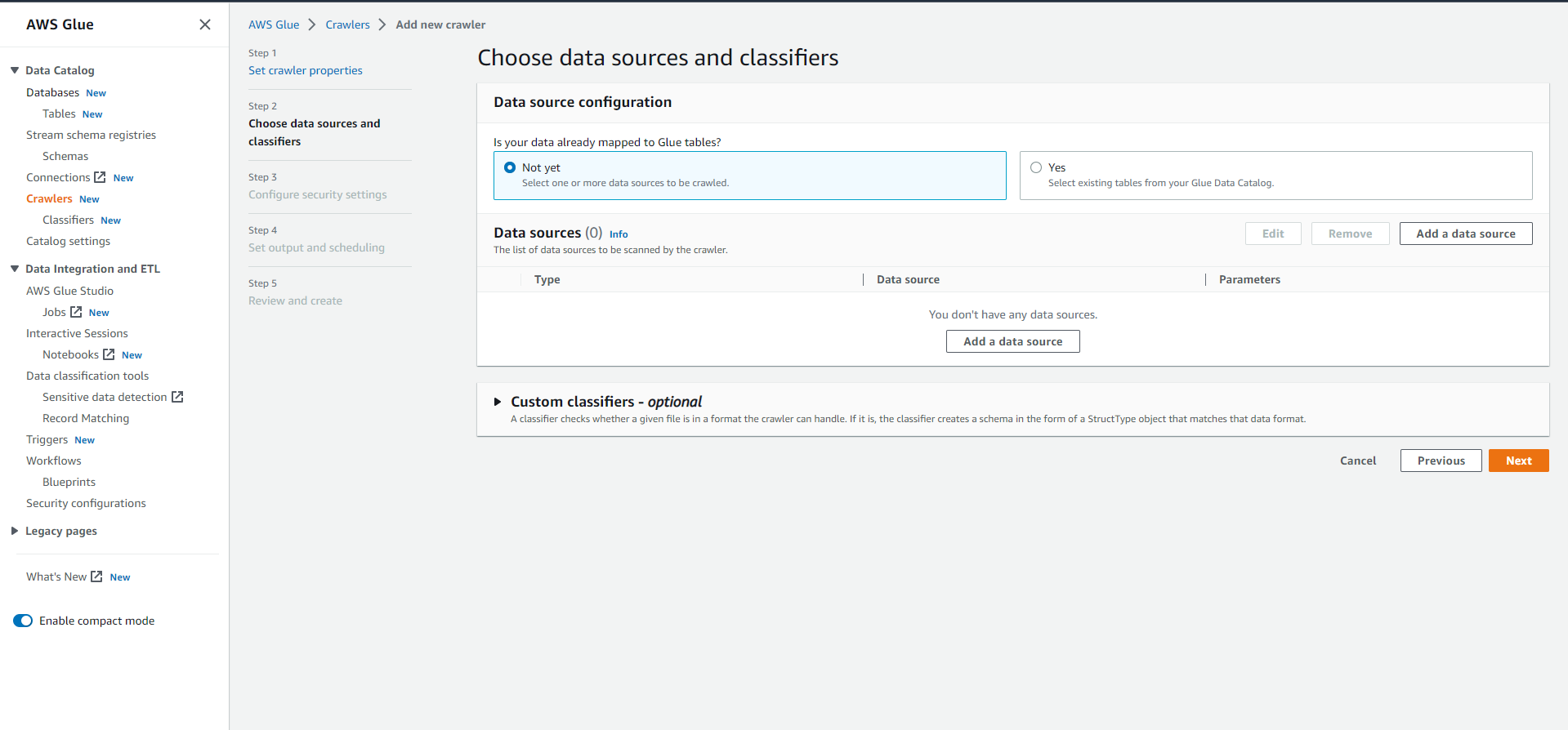
- Configure data source
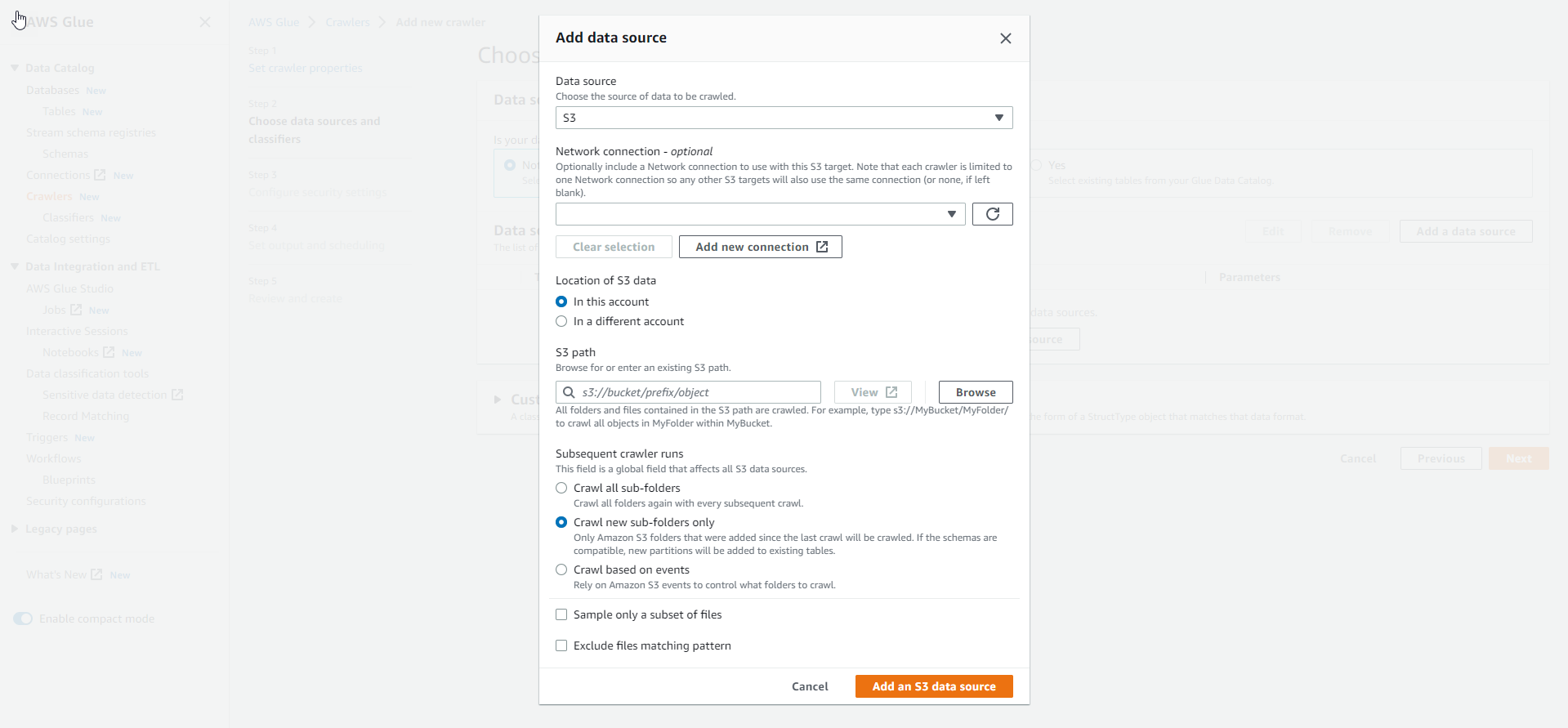
- Select S3 path

- Complete the data source configuration.
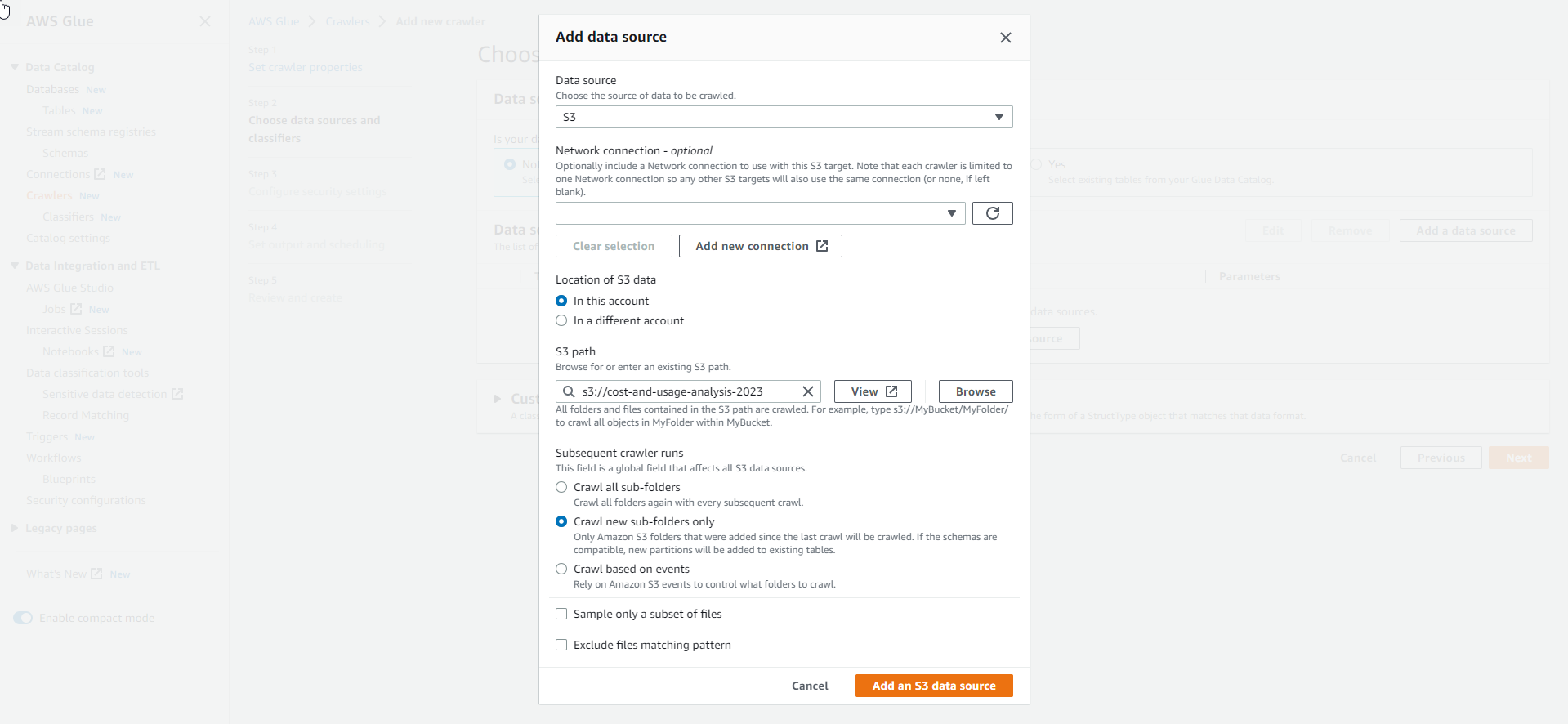
- After configuring the data source, select Next
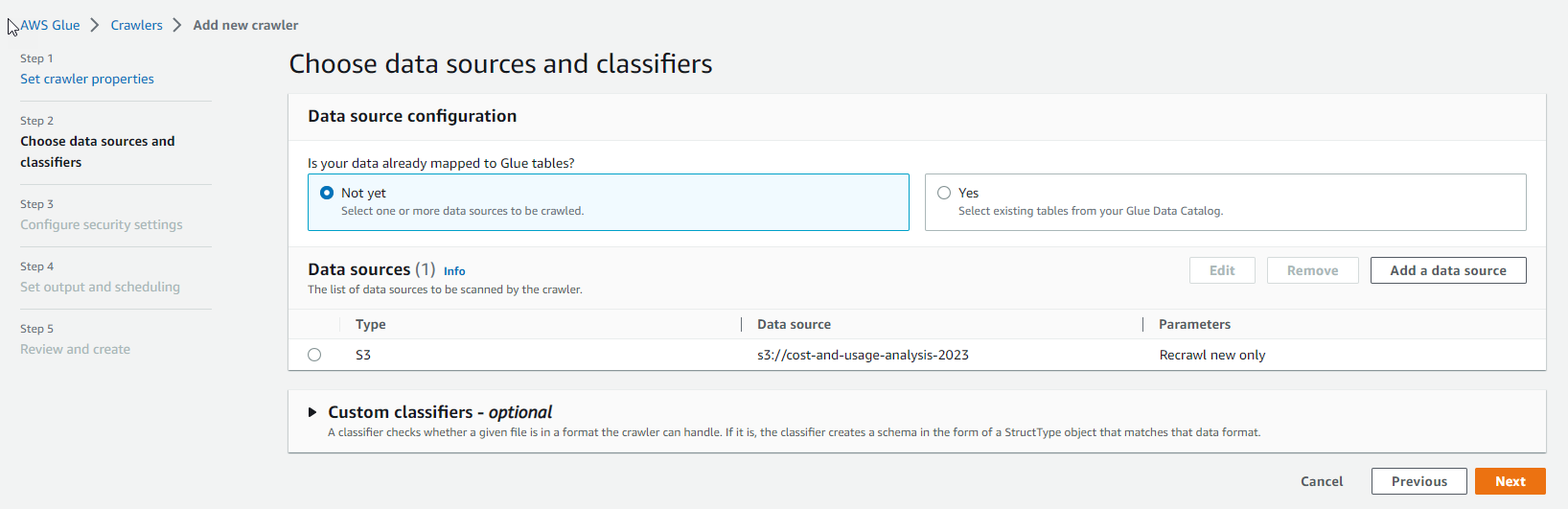
- For security, select Create new IAM role
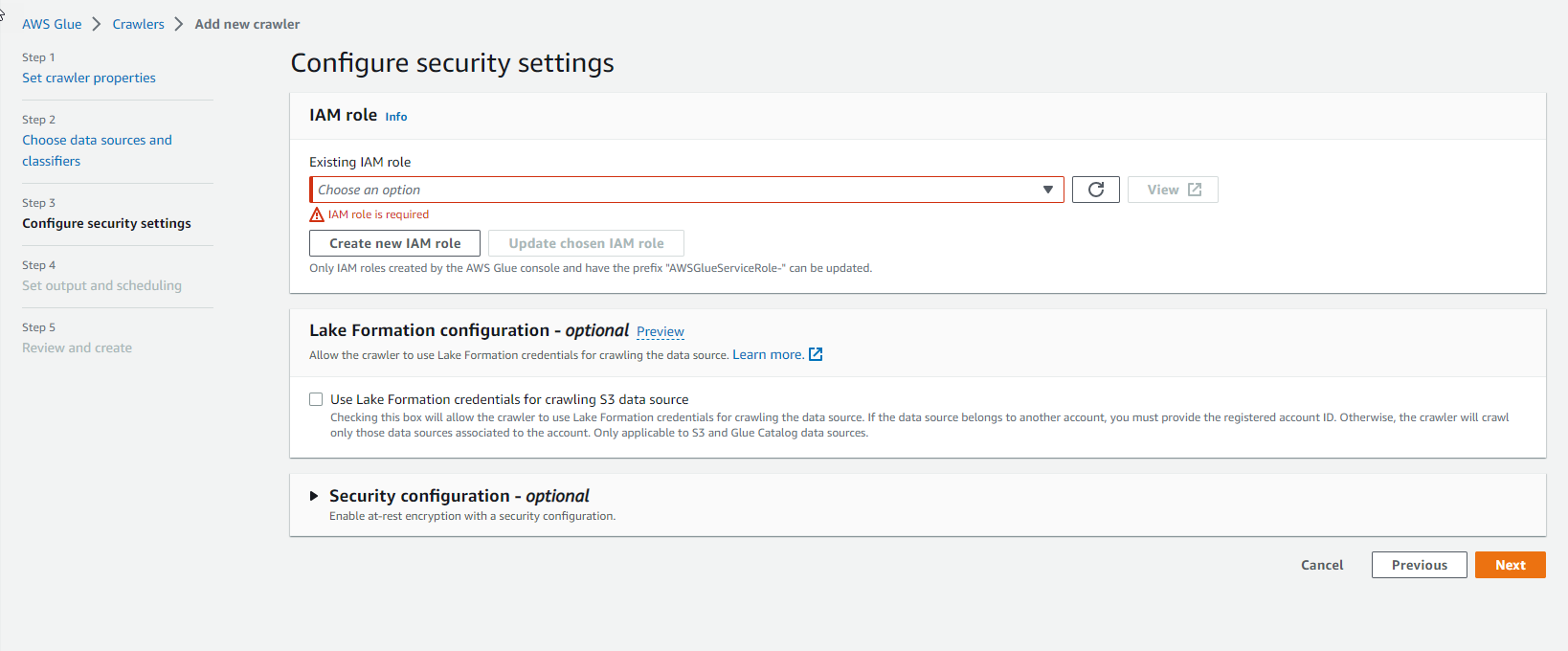
- Enter the role name and select Create
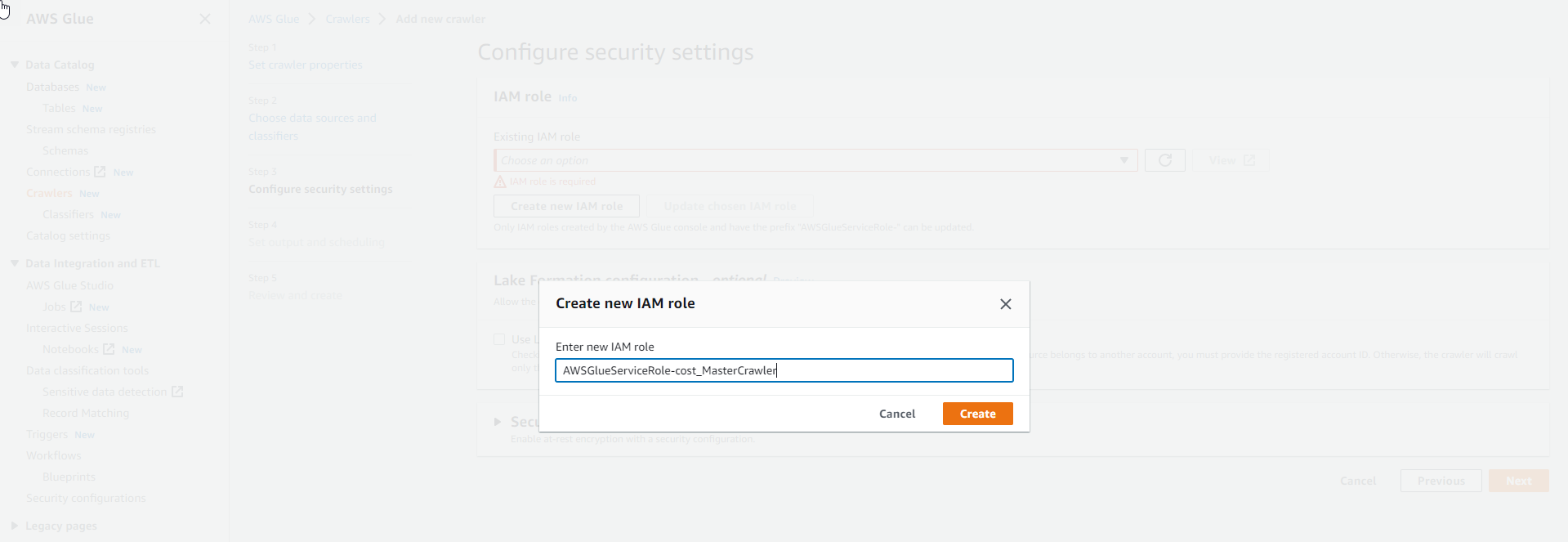
- After creating the role, select Next
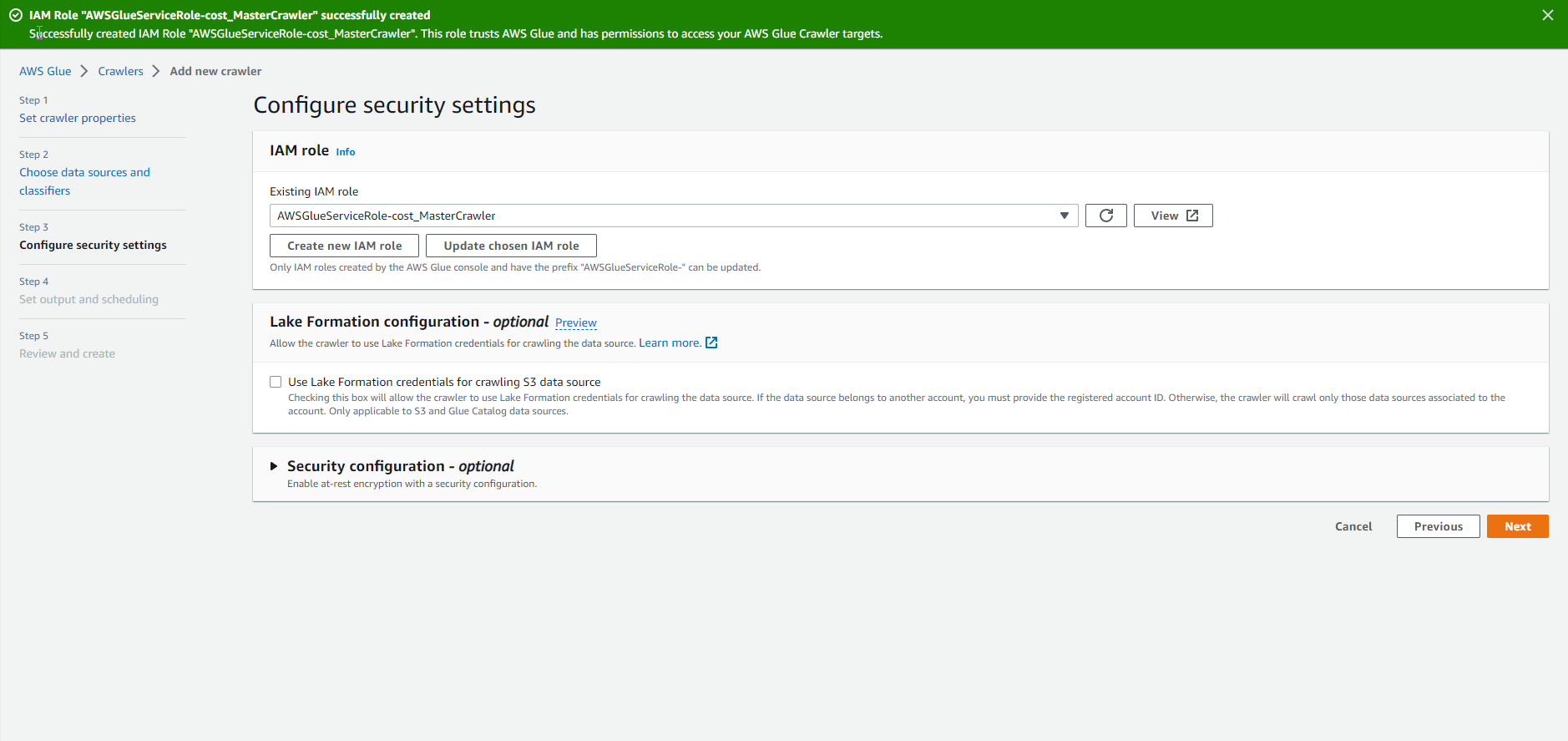
- Implement more database
- Select Add database
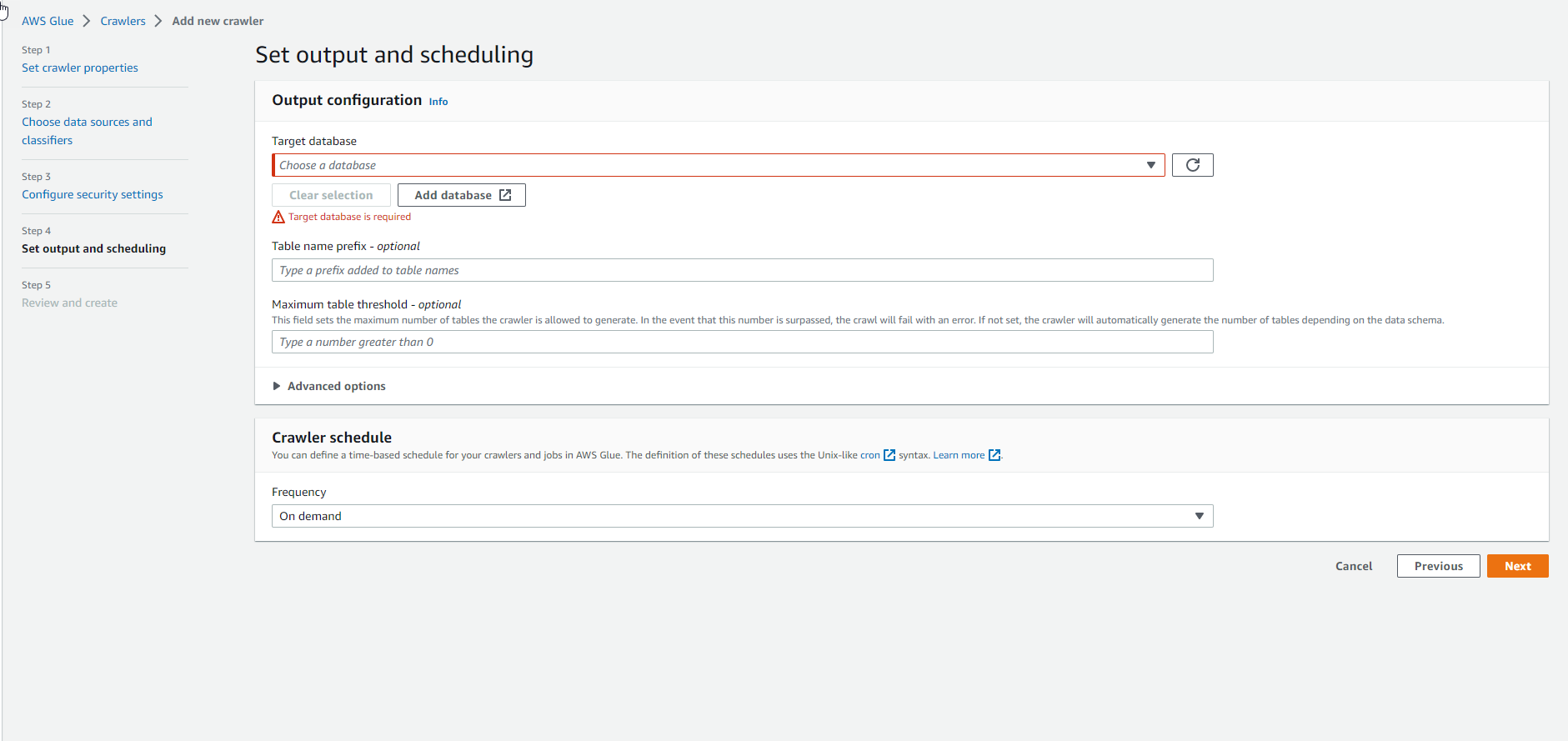
- Enter the database name as
costmaster. Select Create database
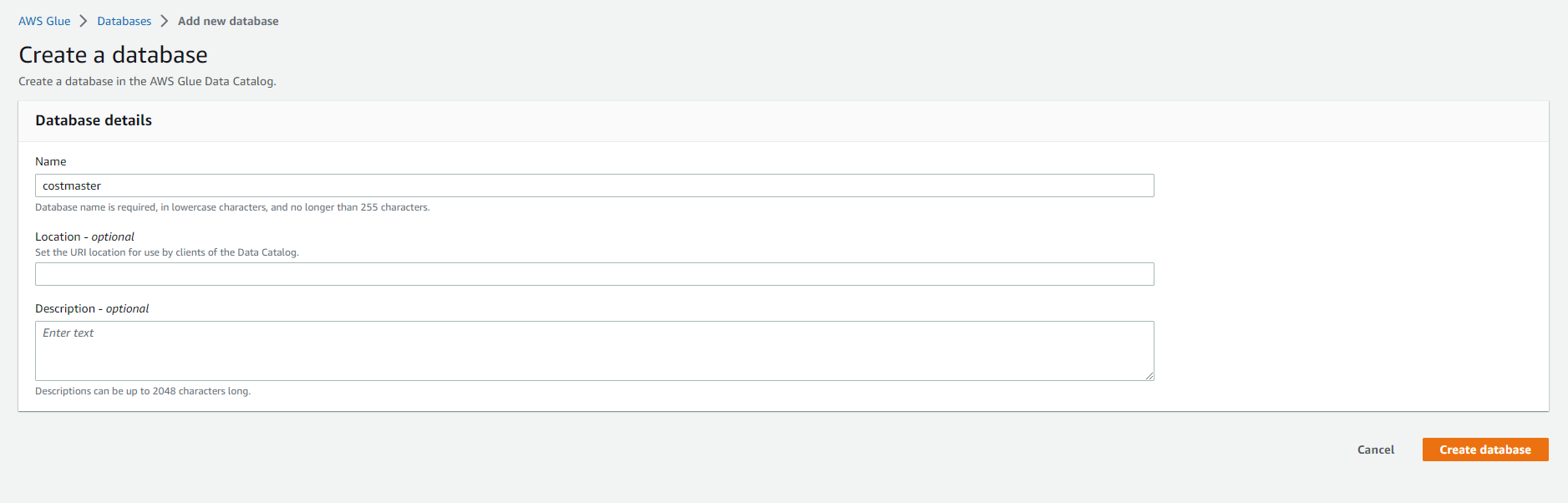
- Complete database creation.
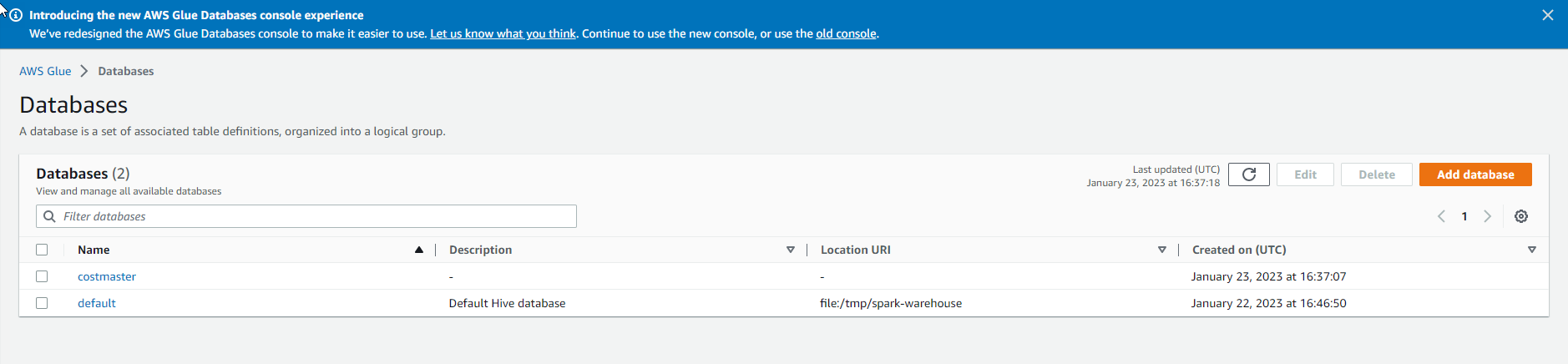
- Add database successfully and select Next
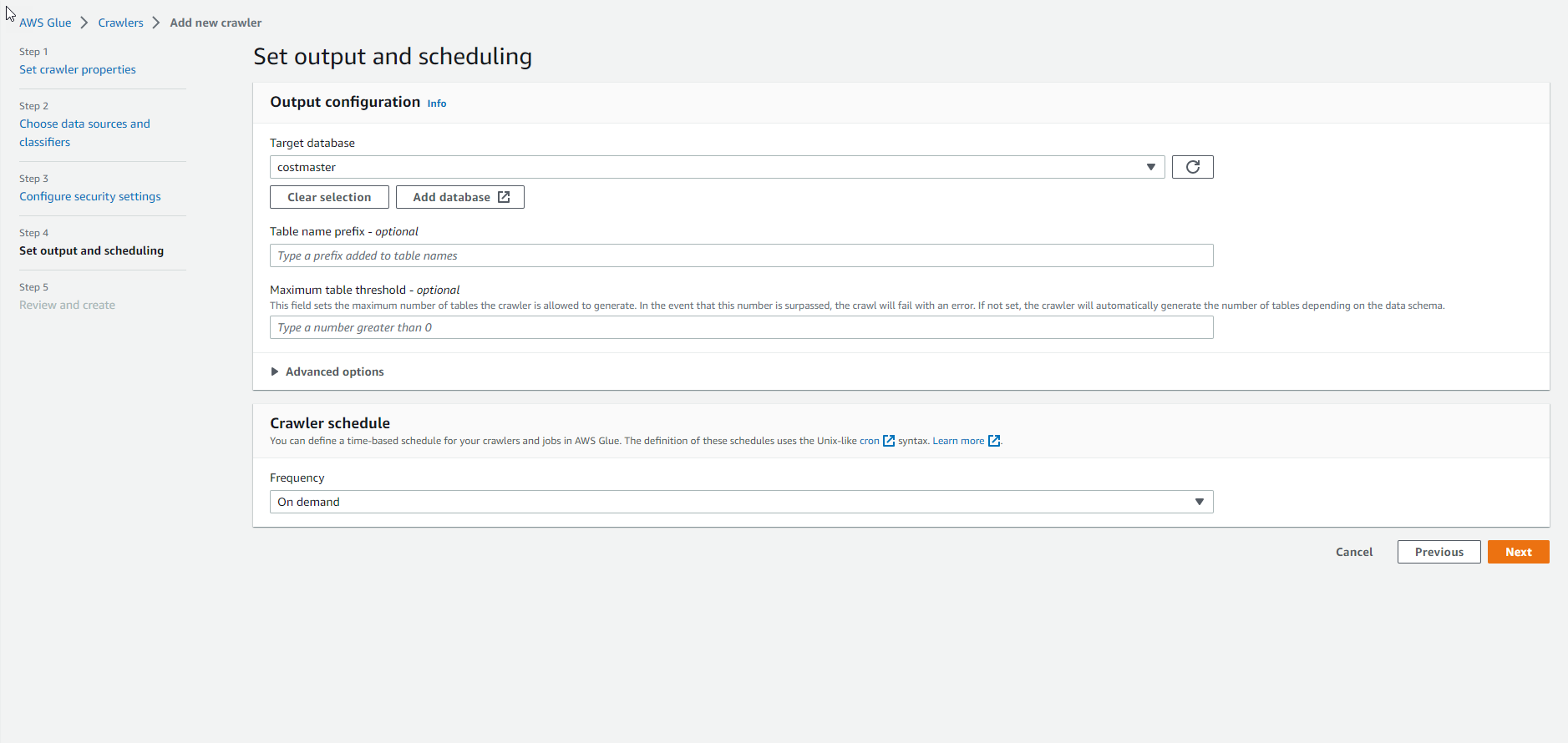
- Check and select Create crawler
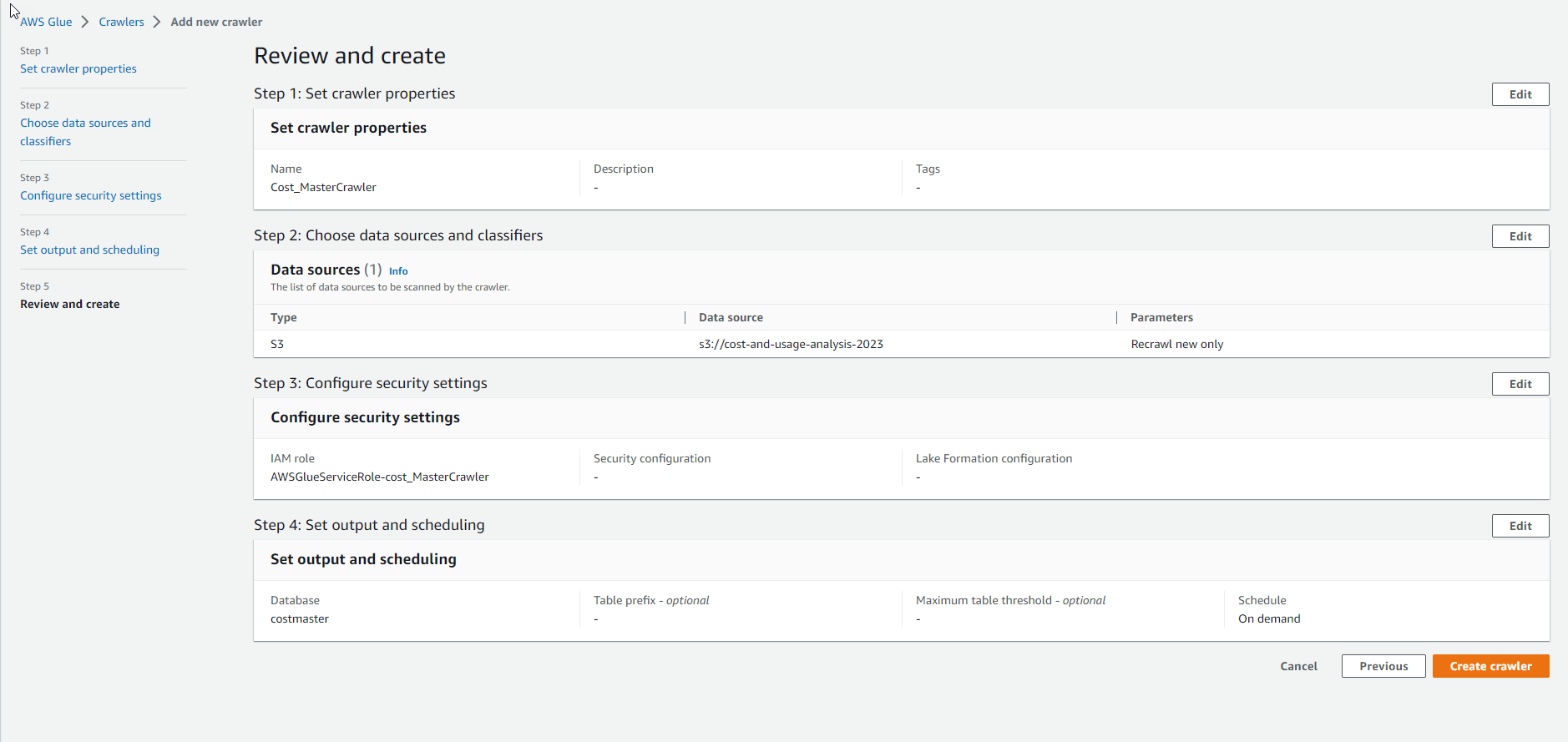
- Complete crawler creation.
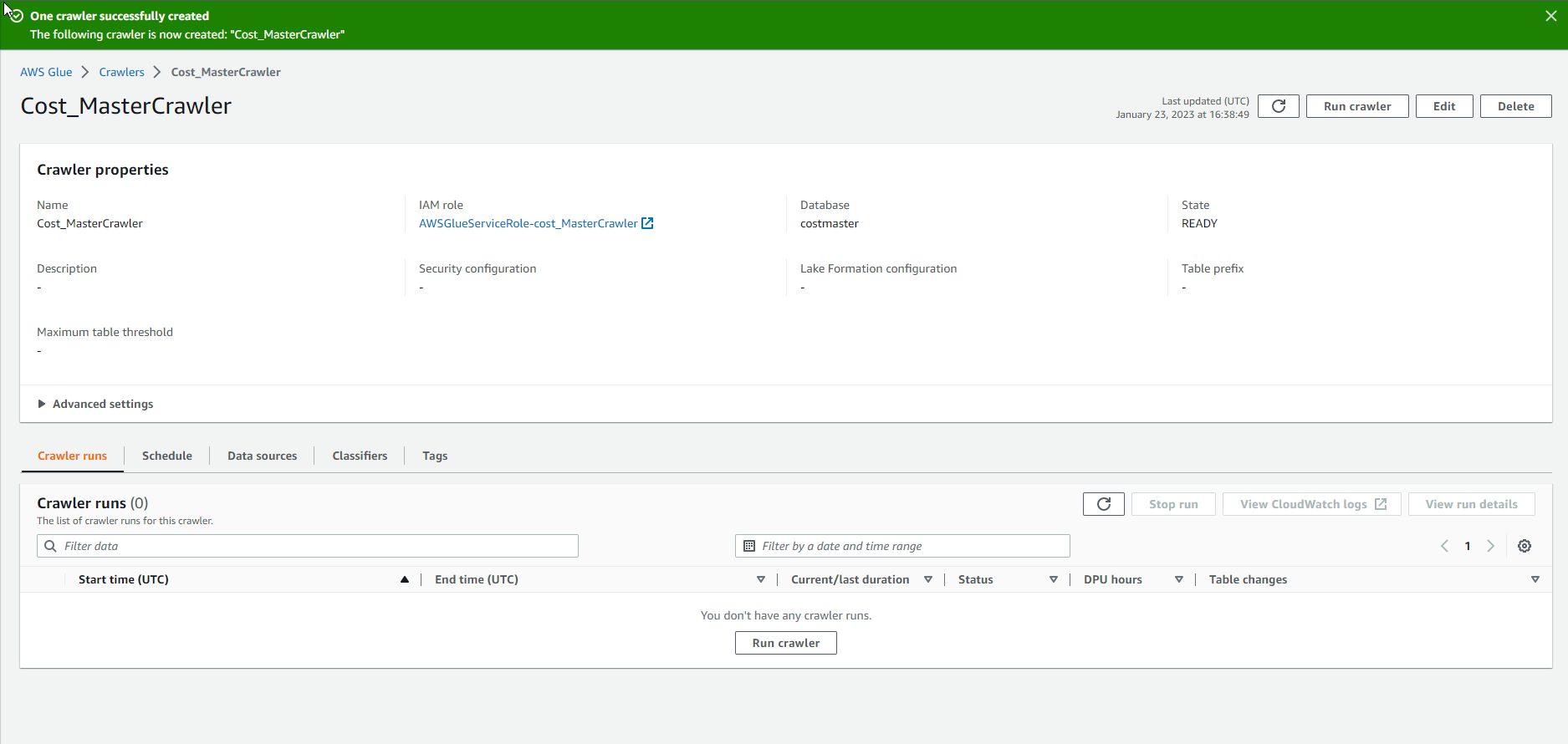
- Select Run crawler
- It takes about 1 minute to initialize the run crawler.
- Initialize run crawler

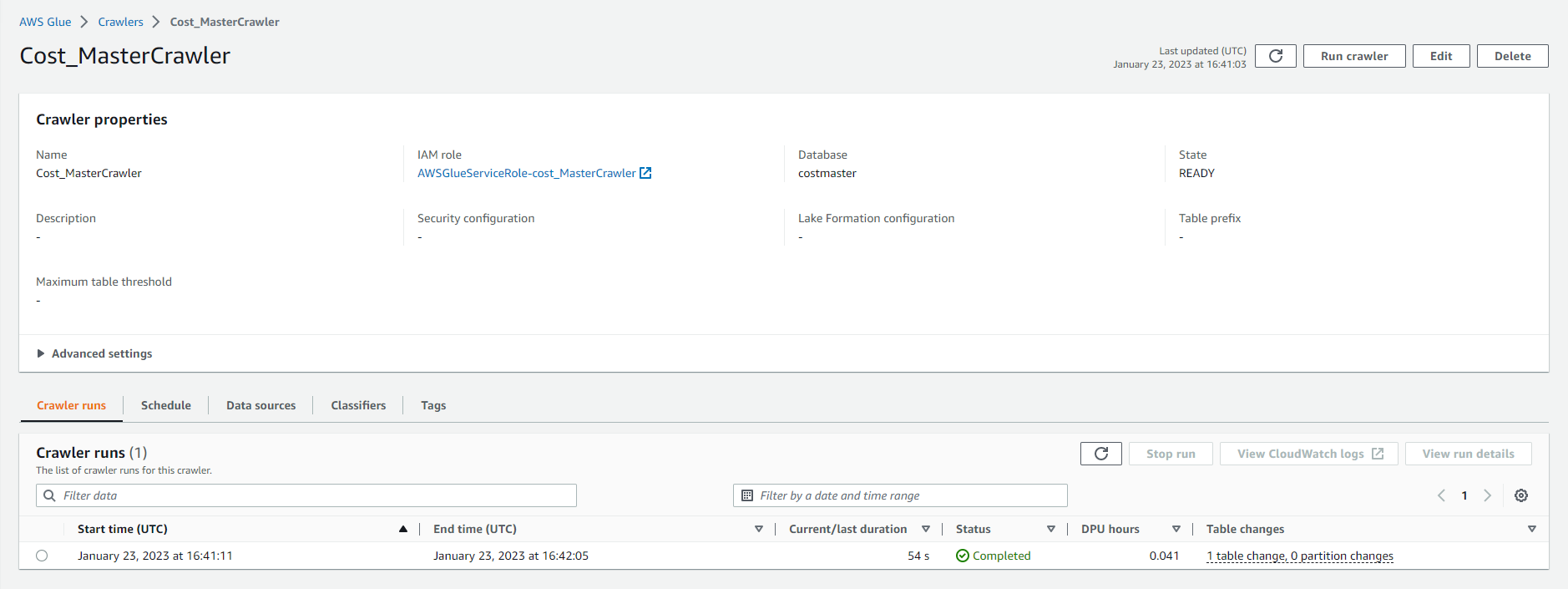
- Run crawler successfully.
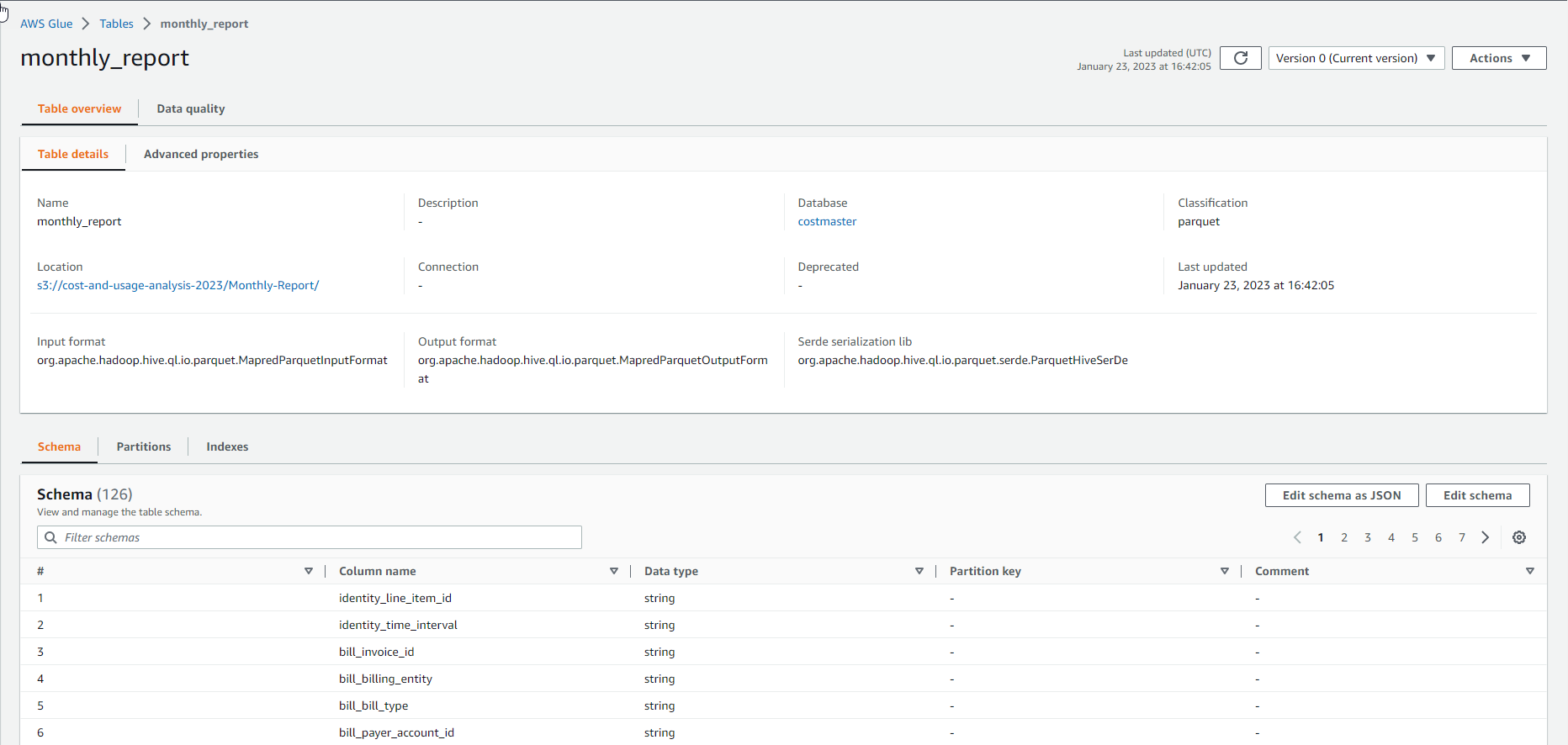
- Check out the AWS Glue Table. We see a data table monthly_report
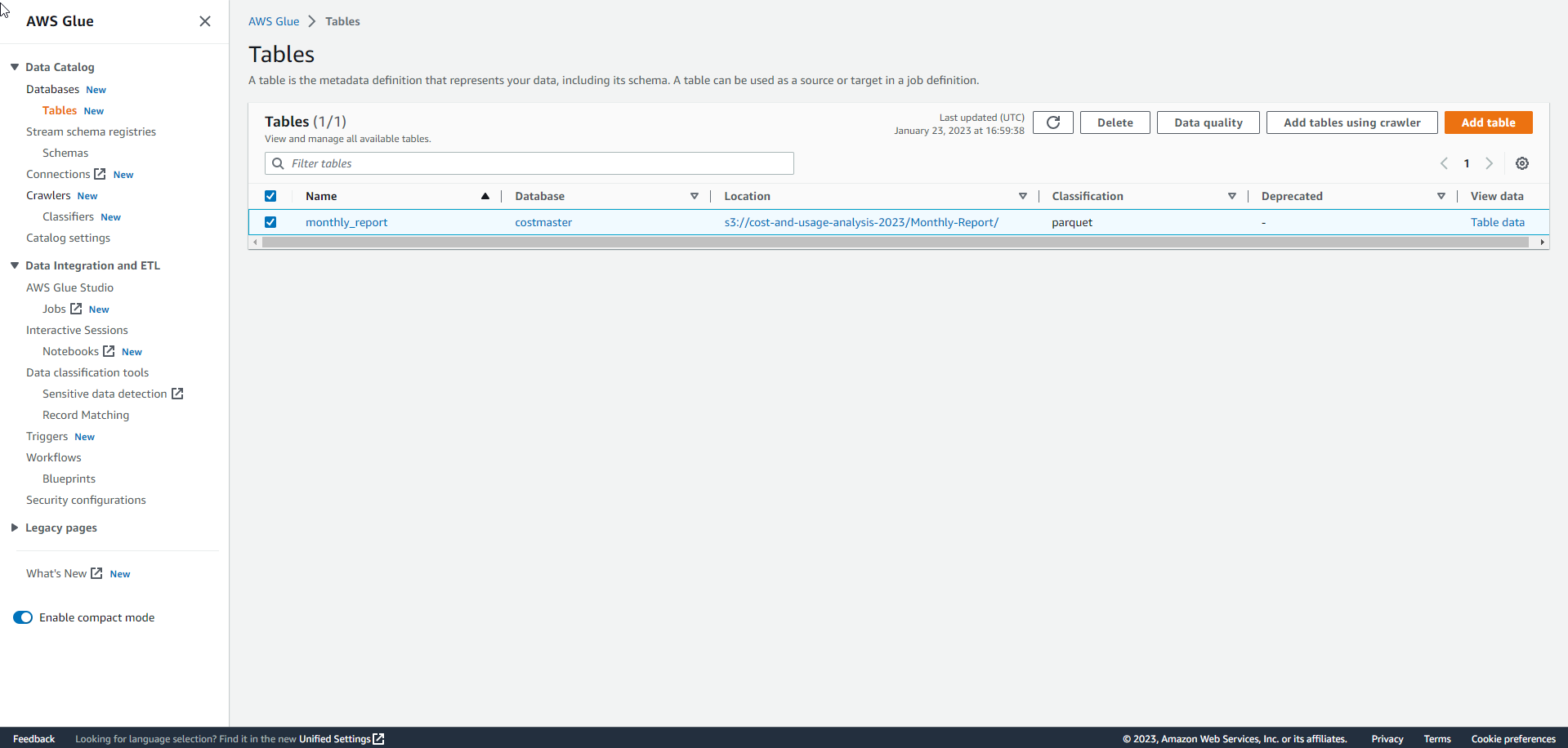
- View detailed data sheet information.